打算在这系列博客把hot100的题扫一遍,分模块来。
岛屿数量 题目描述:
给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
示例 1:
1
2
3
4
5
6
7
输入:grid = [
['1','1','1','1','0'],
['1','1','0','1','0'],
['1','1','0','0','0'],
['0','0','0','0','0']
]
输出:1
示例 2:
1
2
3
4
5
6
7
输入:grid = [
['1','1','0','0','0'],
['1','1','0','0','0'],
['0','0','1','0','0'],
['0','0','0','1','1']
]
输出:3
提示:
m == grid.lengthn == grid[i].length1 <= m, n <= 300grid[i][j]的值为'0'或'1'
思路:
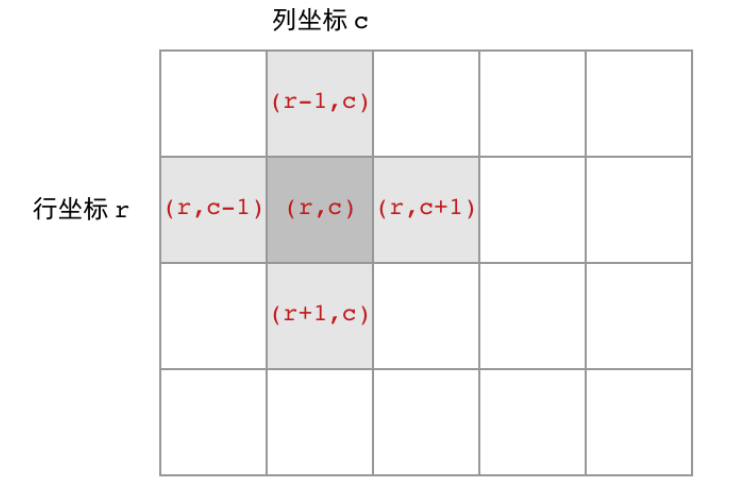
我们所熟悉的 DFS(深度优先搜索)问题通常是在树或者图结构上进行的。而我们今天要讨论的 DFS 问题,是在一种「网格」结构中进行的。岛屿问题是这类网格 DFS 问题的典型代表。如果通过DFS思路去解决这类网格问题,当然也要思考递归的思路。二叉树的递归的边界条件是节点为0,非边界条件是根的左右节点。
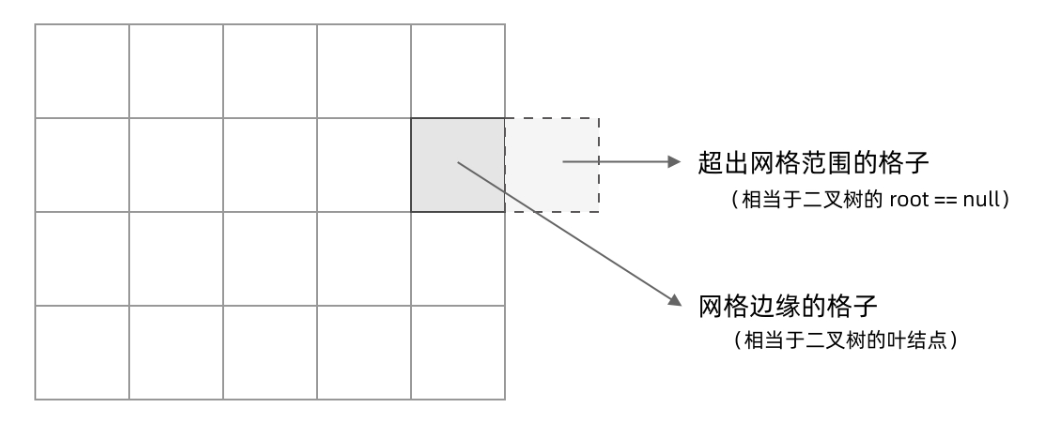
对应过来,相较于二叉树的二叉而言,网格可以是四叉的;二叉树的basecase是叶子节点为0,网格则可以对应到那些超出网格范围的格子。
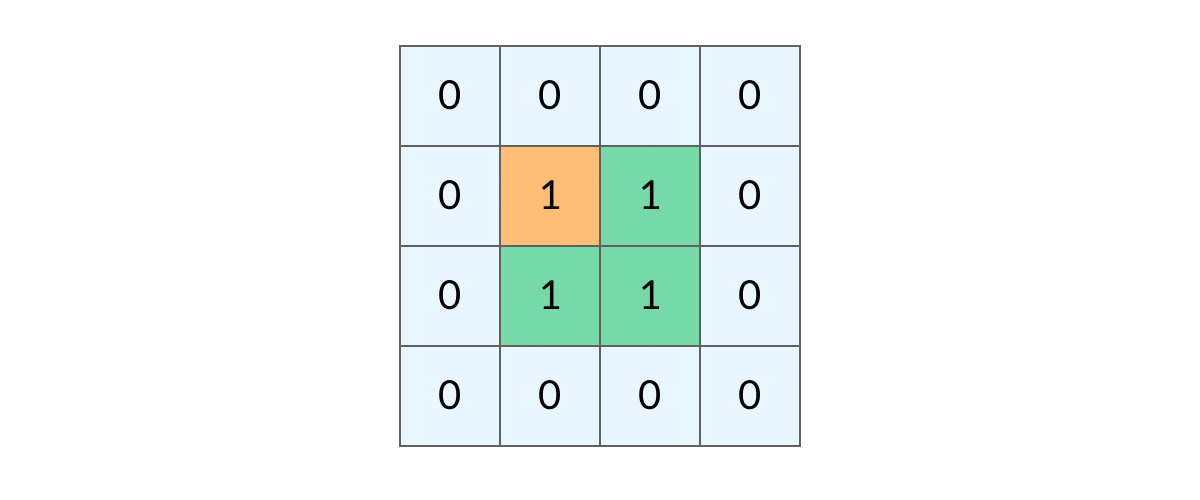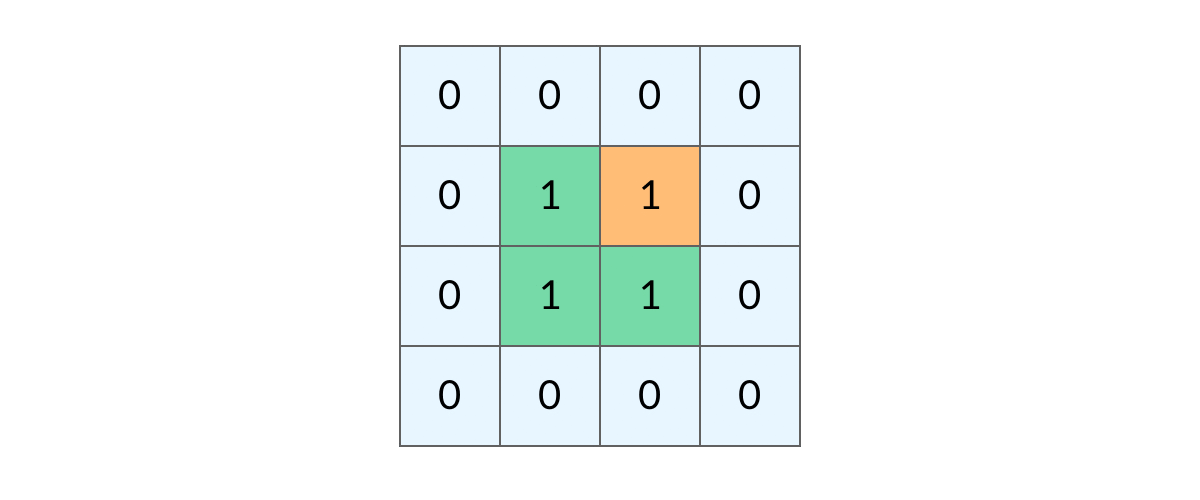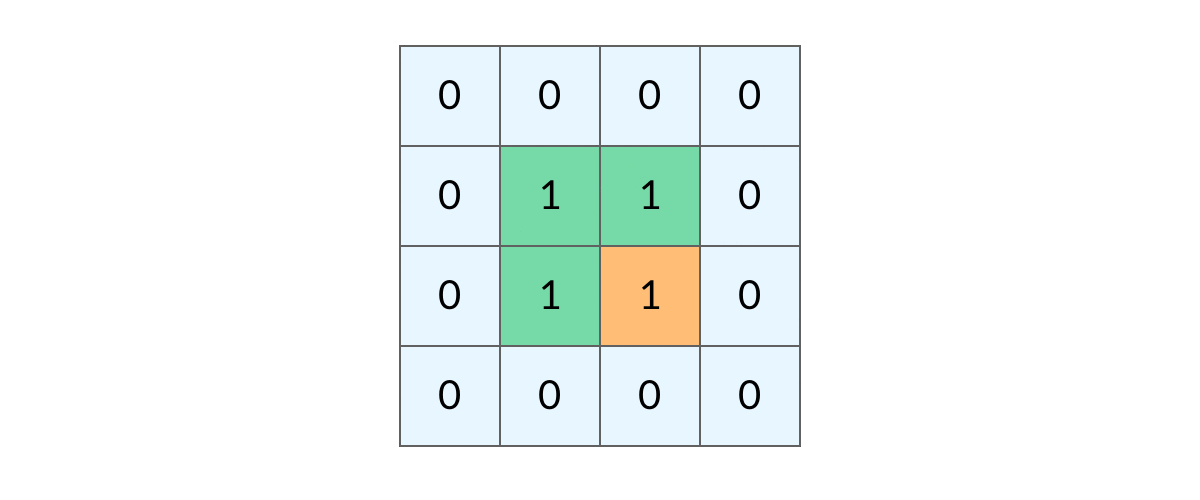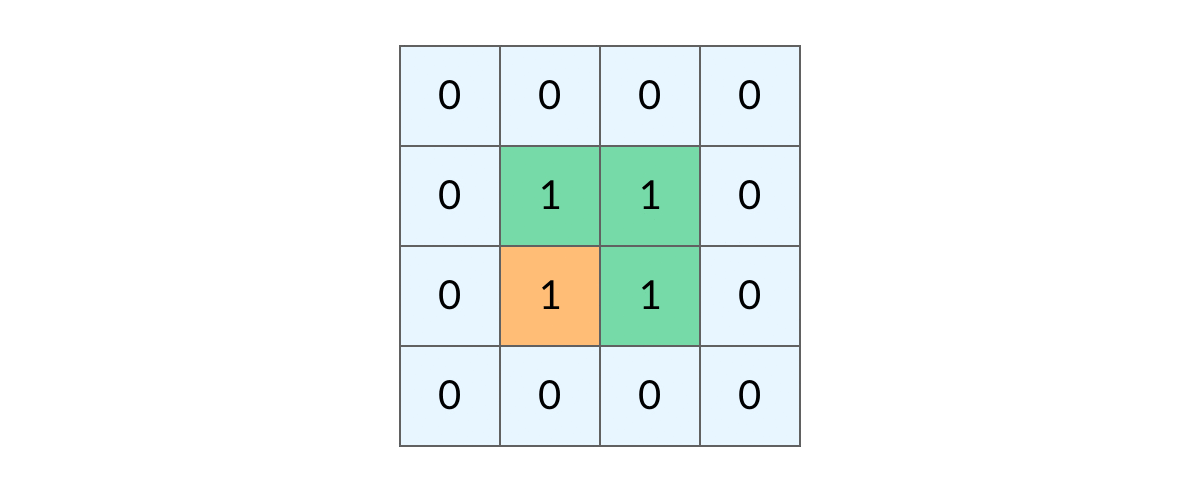
不过和二叉树最大的不同在于,网格有可能会遍历到重复的节点。二叉树是单向的,只要向下遍历,就无法通过下一个节点返回上一个节点,但网格却是互相联通的。这就导致网格的DFS有可能不断兜圈。
如何避免这样的重复遍历呢?答案是标记已经遍历过的格子。以岛屿问题为例,我们需要在所有值为 1 的陆地格子上做 DFS 遍历。每走过一个陆地格子,就把格子的值改为 2,这样当我们遇到 2 的时候,就知道这是遍历过的格子了。也就是说,每个格子可能取三个值:
0 —— 海洋格子 1 —— 陆地格子(未遍历过) 2 —— 陆地格子(已遍历过)
这样遍历时就会是这样。
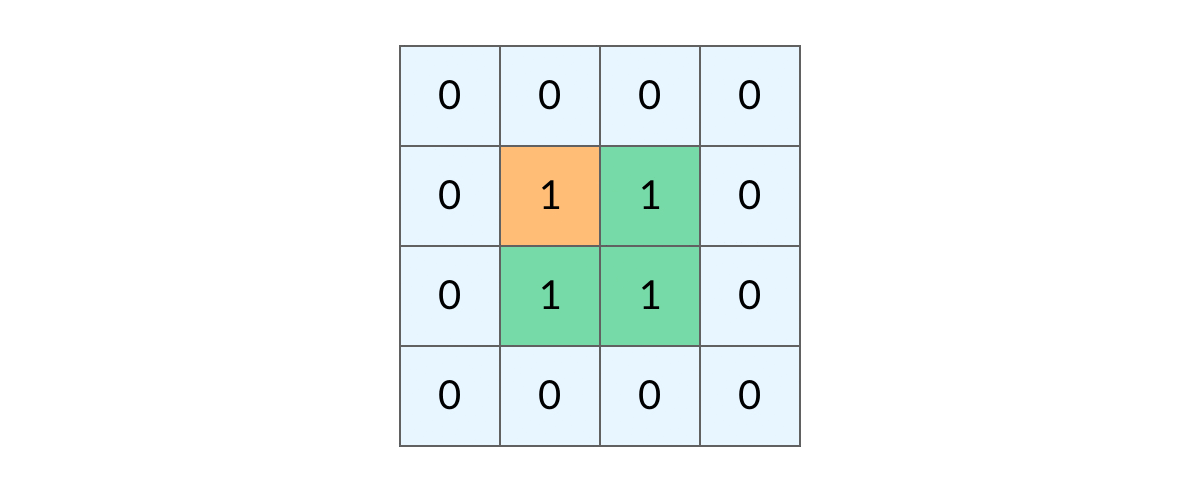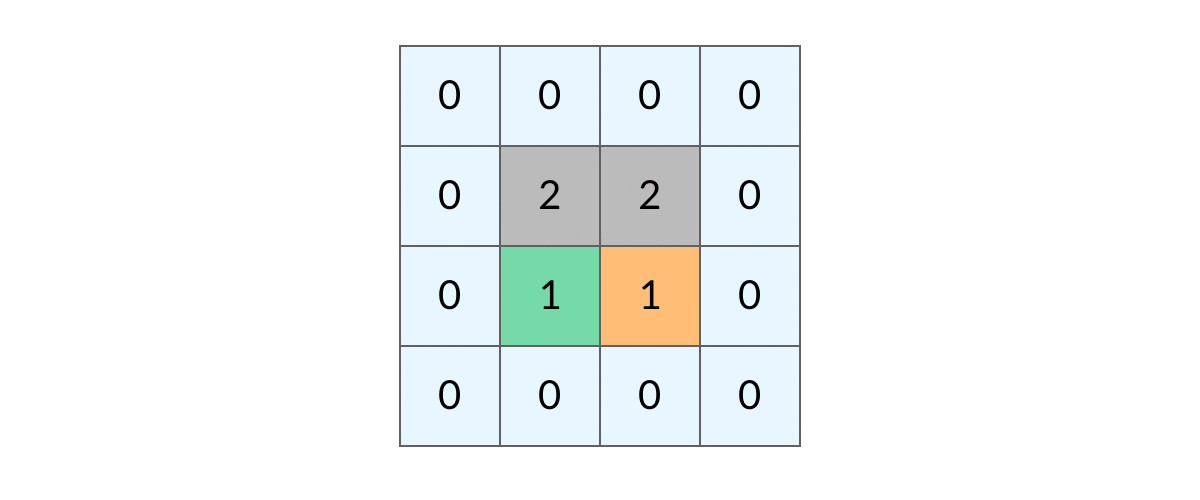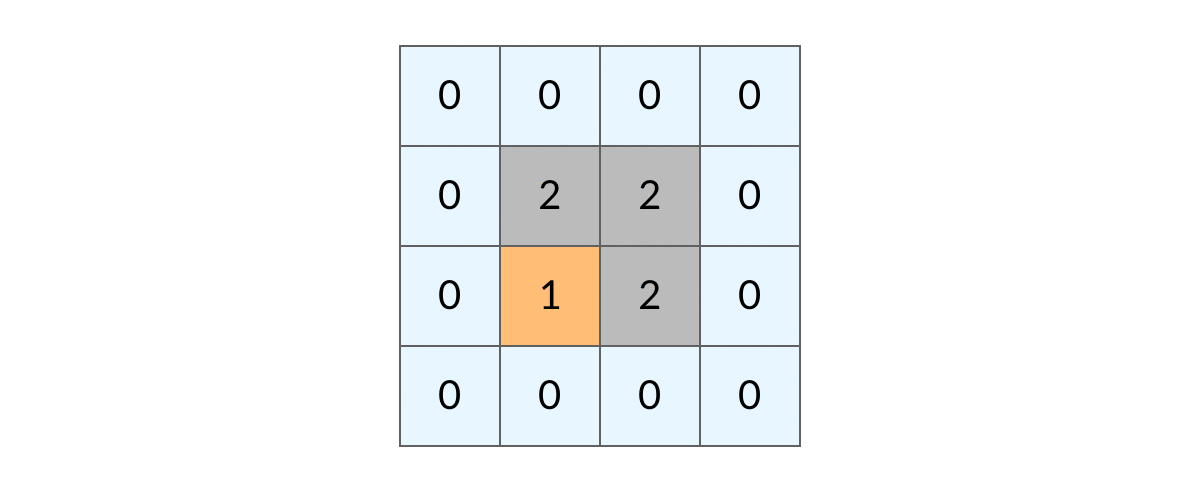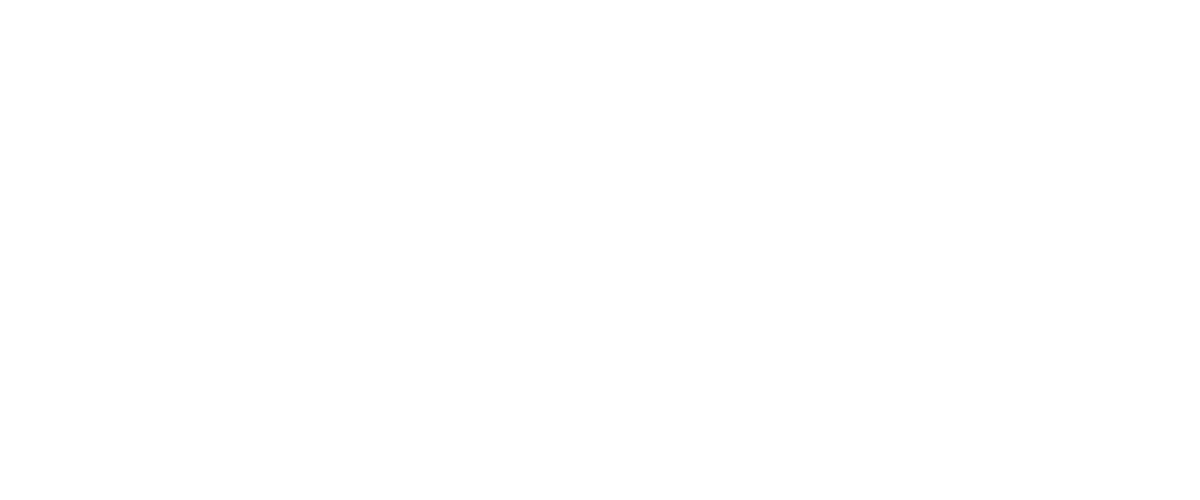
这样,我们就得到了一个岛屿问题、乃至各种网格问题的通用 DFS 遍历方法。以下所讲的几个例题,其实都只需要在 DFS 遍历框架上稍加修改而已。
在一些题解中,可能会把「已遍历过的陆地格子」标记为和海洋格子一样的 0,美其名曰「陆地沉没方法」,即遍历完一个陆地格子就让陆地「沉没」为海洋。这种方法看似很巧妙,但实际上有很大隐患,因为这样我们就无法区分「海洋格子」和「已遍历过的陆地格子」了。如果题目更复杂一点,这很容易出 bug。
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
var numIslands = function(grid) {
const m = grid.length, n = grid[0].length;
function dfs(i, j) {
// 出界,或者不是 '1',就不再往下递归
if (i < 0 || i >= m || j < 0 || j >= n || grid[i][j] !== '1') {
return;
}
grid[i][j] = '2'; // 插旗!避免来回横跳无限递归
dfs(i, j - 1); // 往左走
dfs(i, j + 1); // 往右走
dfs(i - 1, j); // 往上走
dfs(i + 1, j); // 往下走
}
let ans = 0;
for (let i = 0; i < m; i++) {
for (let j = 0; j < n; j++) {
if (grid[i][j] === '1') { // 找到了一个新的岛
dfs(i, j); // 把这个岛插满旗子,这样后面遍历到的 '1' 一定是新的岛
ans++;
}
}
}
return ans;
};
腐烂的橘子 题目描述:
在给定的 m x n 网格 grid 中,每个单元格可以有以下三个值之一:
- 值
0代表空单元格; - 值
1代表新鲜橘子; - 值
2代表腐烂的橘子。
每分钟,腐烂的橘子 周围 4 个方向上相邻 的新鲜橘子都会腐烂。
返回 直到单元格中没有新鲜橘子为止所必须经过的最小分钟数。如果不可能,返回 -1 。
示例 1:
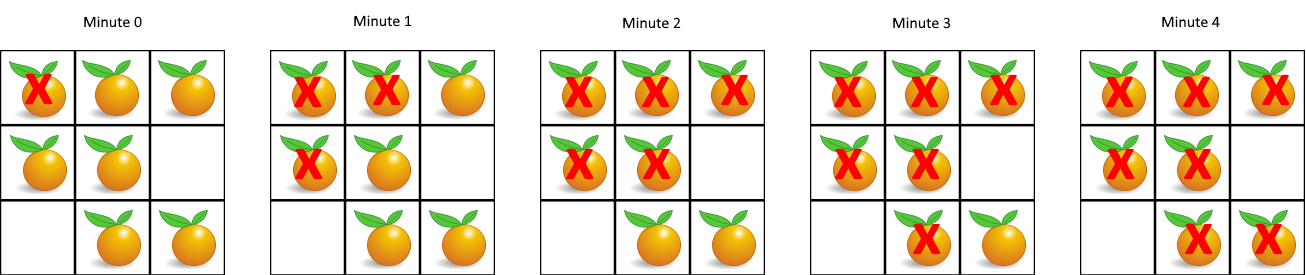
1
2
输入:grid = [[2,1,1],[1,1,0],[0,1,1]]
输出:4
示例 2:
1
2
3
输入:grid = [[2,1,1],[0,1,1],[1,0,1]]
输出:-1
解释:左下角的橘子(第 2 行, 第 0 列)永远不会腐烂,因为腐烂只会发生在 4 个方向上。
示例 3:
1
2
3
输入:grid = [[0,2]]
输出:0
解释:因为 0 分钟时已经没有新鲜橘子了,所以答案就是 0 。
思路:
很明显的BFS,但是由于矩阵的连通性,如果像二叉树那样一个一个节点出然后把它的左右推入,可能会需要处理重复的烂橘子,不过因为实际上标记了 grid[i][j] = 2 ,之后即使重复推入,下次弹出检查时也不是1了,因此不会处理。
最重要的是同一分钟腐烂的橘子同属一批,所以必须一次性取出一次性更新。
| 二叉树BFS | 矩阵多源BFS | |
|---|---|---|
| 每次弹出 | 1个节点 | 整层节点 |
| 原因 | 节点间不会互相影响 | 同层腐烂橘子可能相邻同一个新鲜橘子 |
代码:
循环部分变量写太烂,心智负担过重:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
var orangesRotting = function(grid) {
const height = grid.length;
const width = grid[0].length;
let fresh = 0;
let q = [];
let minuteNeed = 0;
for (let i = 0; i < height; i++) { // 本次遍历收集矩阵中新鲜的和腐烂的橘子位置
for (let j = 0; j < width; j++) {
if (grid[i][j] === 1) {
fresh++;
}
if (grid[i][j] === 2) {
q.push([i, j]);
}
}
}
while (fresh && q.length) {
minuteNeed++;
const temQ = q; // 一次全部取出,如果一个一个shift,有可能会push进去重复的烂橘子
q = [];
for (let i = 0; i < temQ.length; i++) { // 处理四个方向
if ((temQ[i][0] - 1 >= 0) && grid[temQ[i][0] - 1][temQ[i][1]] === 1) {
fresh--;
grid[temQ[i][0] - 1][temQ[i][1]] += 1;
q.push([temQ[i][0] - 1, temQ[i][1]]);
}
if ((temQ[i][0] + 1 < height) && grid[temQ[i][0] + 1][temQ[i][1]] === 1) {
fresh--;
grid[temQ[i][0] + 1][temQ[i][1]] += 1;
q.push([temQ[i][0] + 1, temQ[i][1]]);
}
if ((temQ[i][1] - 1 >= 0) && grid[temQ[i][0]][temQ[i][1] - 1] === 1) {
fresh--;
grid[temQ[i][0]][temQ[i][1] - 1] += 1;
q.push([temQ[i][0], temQ[i][1] - 1]);
}
if ((temQ[i][1] + 1 < width) && grid[temQ[i][0]][temQ[i][1] + 1] === 1) {
fresh--;
grid[temQ[i][0]][temQ[i][1] + 1] += 1;
q.push([temQ[i][0], temQ[i][1] + 1]);
}
}
}
return fresh ? -1 : minuteNeed;
};
灵神的做法,用for-of语法糖,简单易懂:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
var orangesRotting = function(grid) {
const m = grid.length, n = grid[0].length;
let fresh = 0;
let q = [];
for (let i = 0; i < m; i++) {
for (let j = 0; j < n; j++) {
if (grid[i][j] === 1) {
fresh++; // 统计新鲜橘子个数
} else if (grid[i][j] === 2) {
q.push([i, j]); // 一开始就腐烂的橘子
}
}
}
let ans = 0;
while (fresh && q.length) {
ans++; // 经过一分钟
const tmp = q;
q = [];
for (const [x, y] of tmp) { // 已经腐烂的橘子
for (const [i, j] of [[x - 1, y], [x + 1, y], [x, y - 1], [x, y + 1]]) { // 四方向
if (0 <= i && i < m && 0 <= j && j < n && grid[i][j] === 1) { // 新鲜橘子
fresh--;
grid[i][j] = 2; // 变成腐烂橘子
q.push([i, j]);
}
}
}
}
return fresh ? -1 : ans;
};
课程表 题目描述:
你这个学期必须选修 numCourses 门课程,记为 0 到 numCourses - 1 。
在选修某些课程之前需要一些先修课程。 先修课程按数组 prerequisites 给出,其中 prerequisites[i] = [ai, bi] ,表示如果要学习课程 ai 则 必须 先学习课程 bi 。
- 例如,先修课程对
[0, 1]表示:想要学习课程0,你需要先完成课程1。
请你判断是否可能完成所有课程的学习?如果可以,返回 true ;否则,返回 false 。
示例 1:
1
2
3
输入:numCourses = 2, prerequisites = [[1,0]]
输出:true
解释:总共有 2 门课程。学习课程 1 之前,你需要完成课程 0 。这是可能的。
示例 2:
1
2
3
输入:numCourses = 2, prerequisites = [[1,0],[0,1]]
输出:false
解释:总共有 2 门课程。学习课程 1 之前,你需要先完成课程 0 ;并且学习课程 0 之前,你还应先完成课程 1 。这是不可能的。
提示:
1 <= numCourses <= 20000 <= prerequisites.length <= 5000prerequisites[i].length == 20 <= ai, bi < numCoursesprerequisites[i]中的所有课程对 互不相同
思路:
这题很明显能看出需要判断这个课程表是否是一个有向无环图,如果无环,就能顺利修完所有课程。最典型的判断环的方式是DFS,所以这题可以考虑用DFS完成。
用拓扑排序也可以判断是否有环,方法也很简单,不断删掉入度为0的节点,如果不能把所有节点全部删除,就说明有环。
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
var canFinish = function(numCourses, prerequisites) {
// 邻接表:graph[pre] = [cur1, cur2, ...] 表示pre是谁的前置课
const graph = Array.from({ length: numCourses }, () => []);
// 入度数组:indegree[i] = 课程i有几个前置课,表示i的入度
const indegree = new Array(numCourses).fill(0);
for (const [cur, pre] of prerequisites) {
graph[pre].push(cur); // pre → cur,pre是cur的前置
indegree[cur]++; // cur的入度+1
}
// 所有入度为0的课程入队(没有前置课,可以直接选)
const q = []; // 队列:表示当前可以选的课
for (let i = 0; i < numCourses; i++) {
if (indegree[i] === 0) q.push(i);
}
let count = 0; // 已选课程数
while (q.length) {
const class = q.shift(); // 选掉一门课
count++;
// 这门课选完了,依赖它的后续课入度-1
for (const nextClass of graph[class]) {
indegree[nextClass]--;
// 入度减到0,说明前置课都选完了,本门课可以被选
if (indegree[nextClass] === 0) q.push(nextClass);
}
}
// 能选完所有课 = 无环,选不完 = 有环
return count === numCourses;
};
实现 Trie (前缀树) 题目描述:
Trie(发音类似 “try”)或者说 前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景,例如自动补全和拼写检查。
请你实现 Trie 类:
Trie()初始化前缀树对象。void insert(String word)向前缀树中插入字符串word。boolean search(String word)如果字符串word在前缀树中,返回true(即,在检索之前已经插入);否则,返回false。boolean startsWith(String prefix)如果之前已经插入的字符串word的前缀之一为prefix,返回true;否则,返回false。
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
输入
["Trie", "insert", "search", "search", "startsWith", "insert", "search"]
[[], ["apple"], ["apple"], ["app"], ["app"], ["app"], ["app"]]
输出
[null, null, true, false, true, null, true]
解释
Trie trie = new Trie();
trie.insert("apple");
trie.search("apple"); // 返回 True
trie.search("app"); // 返回 False
trie.startsWith("app"); // 返回 True
trie.insert("app");
trie.search("app"); // 返回 True
提示:
1 <= word.length, prefix.length <= 2000word和prefix仅由小写英文字母组成insert、search和startsWith调用次数 总计 不超过3 * 104次
思路:
要自己定义一个数据结构,看题中描述,我们可以创建一个递归定义的26叉树,同时在每个节点增加一个标记,用来判断这个节点是不是已经成为了某个单词的结尾。对于插入搜索和前缀这三个方法,都具有类似的向下搜索逻辑,插入打标记,search查标记,startsWith不管标记。
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
var Trie = function() {
this.children = {}; // 子节点:{ 'a': Trie, 'b': Trie, ... }
this.isEnd = false; // 是否是某个单词的结尾
};
Trie.prototype.insert = function(word) {
let node = this;
for (const ch of word) {
if (!node.children[ch]) {
node.children[ch] = new Trie(); // 没有这个字母的路径,新建
}
node = node.children[ch]; // 沿着路径往下走
}
node.isEnd = true; // 单词结尾打标记
};
Trie.prototype.search = function(word) {
let node = this;
for (const ch of word) {
if (!node.children[ch]) return false; // 路径断了,单词不存在
node = node.children[ch];
}
return node.isEnd; // 路径走完了,还要确认是单词结尾
};
Trie.prototype.startsWith = function(prefix) {
let node = this;
for (const ch of prefix) {
if (!node.children[ch]) return false;
node = node.children[ch];
}
return true; // 路径走完就行,不要求是单词结尾
};