跟着灵茶山艾府大佬学习算法思路的day14(并没有在一个月内掌握hot100)
b站链接如下:
在默认情况下,子数组和子串是连续的,子序列不一定是连续的,但会保证子序列中的元素顺序仍遵循在原序列中的顺序。

最长公共子序列 题目描述:
给定两个字符串 text1 和 text2,返回这两个字符串的最长 公共子序列 的长度。如果不存在 公共子序列 ,返回 0 。
一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。
- 例如,
"ace"是"abcde"的子序列,但"aec"不是"abcde"的子序列。
两个字符串的 公共子序列 是这两个字符串所共同拥有的子序列。
示例 1:
1
2
3
输入:text1 = "abcde", text2 = "ace"
输出:3
解释:最长公共子序列是 "ace" ,它的长度为 3 。
示例 2:
1
2
3
输入:text1 = "abc", text2 = "abc"
输出:3
解释:最长公共子序列是 "abc" ,它的长度为 3 。
示例 3:
1
2
3
输入:text1 = "abc", text2 = "def"
输出:0
解释:两个字符串没有公共子序列,返回 0 。
提示:
1 <= text1.length, text2.length <= 1000text1和text2仅由小写英文字符组成。
思路:
子序列的构建仍然可以使用选或不选的思路。

在遍历过程中,元素有两种情况,s[i]等于或者不等于t[i];在考虑元素是否选入时,一共可能有四种情况,s选t不选,s不选t选,st都不选,st都选。
我们知道如果遇到的字符符合了s[i] = t[i]的条件,那么的确是可以选或者不选,都不影响公共子序列的产出,但因为所求的是最长的公共子序列,那么选入符合的字符一定会比不选入好。而如果s[i] ≠ t[j],就一定不能两个元素都选入,又因为st都不选的结果一定不优于另外两种,所以st都不选这一情况会被包含在另外两种情况里。
要注意,即使两个字符不匹配时,去掉任意一边可能比全部去掉更优,也不意味着我们将没有被去掉的另一边考虑进了子序列中,此时没有被去掉的另一边只能作为备选。也因此,我们只在两端匹配时加分,不匹配时不加分。
根据这点,最后可以得到的情况会简化如下。
1
2
s[i] ≠ t[j]:max(不选s[i], 不选t[j]) → max(dp[i-1][j], dp[i][j-1])
s[i] = t[j]:都选一定最优 → dp[i-1][j-1] + 1
最后可以一起合并为一条式子,同时包含相等和不相等的条件。
相等时三个取 max,dp[i-1][j-1] + 1 最大;不相等时第三项退化为 dp[i-1][j-1],被前两项覆盖。
1
2
3
4
5
6
7
8
if (s[i] === t[j]) {
dp[i][j] = dp[i-1][j-1] + 1;
} else {
dp[i][j] = Math.max(dp[i-1][j], dp[i][j-1]);
}
// 或这样
dp[i][j] = Math.max(dp[i-1][j], dp[i][j-1], dp[i-1][j-1] + (s[i] === t[j] ? 1 : 0));
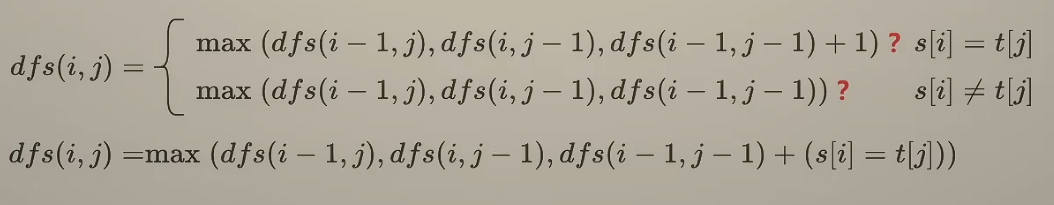
当 s[i] = c, t[j] = c(字符相等)时:
1
2
3
dp[i-1][j-1] + 1 → "ab"的LCS长度2 + 1 = 3 ← 正确答案
dp[i-1][j] → s去掉c,"abcd"和"abc"的LCS = 3
dp[i][j-1] → t去掉c,"abcdc"和"ab"的LCS = 2
但图里假设了一个矛盾情况,如果 dp[i-1][j] > dp[i-1][j-1] + 1,那就出问题了。
因为 dp[i-1][j] 是 s[0..i-1] 和 t[0..j] 的 LCS,而 t[j] 就是那个相等的 c。s[0..i-1] 里没有用到当前的 c,却能比用上 c 还长?这不可能。
所以实际上 dp[i-1][j-1] + 1 一定 ≥ 另外两项,不会出现矛盾。
也可以这么理解,在二叉结构里面,dp[i-1][j] 和 dp[i][j-1]同时是dp[i-1][j-1] + 1和dp[i-1][j-1]的平级问题,它们都是dp[i][j]的子问题,而dp[i-1][j-1] + 1比 dp[i-1][j-1] 严格多了 1,而另外两项顶多比 dp[i-1][j-1] 再多一个 1(想要再大于dp[i-1][j-1] + 1就不可能,因为只多选了一个字符)。
这体现了dp的核心特点,最优子结构,全局最优解一定包含子问题的最优解,如果知道所有更小规模的子问题的最优解,拼起来就是当前规模的最优解。因此s[i] = t[j] 时,dp[i-1][j-1] + 1 一定是最大的。

滚动数组的改写是类似0-1背包和完全背包的,0-1背包需求所求元素上方和左斜上方的旧数组元素,完全背包需求所求元素上方的旧元素和左边的新元素,本题综合了这两个背包问题,需求的是上方和左斜上方的旧数组元素,也同时需求左边的新元素。
已知滚动数组的方案可以同时满足0-1背包和完全背包,本题更新时所需的元素和0-1背包和完全背包是一致的,所以滚动数组自然也能完成本题。这题难的是如何使用一个数组完成,模拟一下很明显能发现,左斜上方的旧数组元素和左边的新元素是冲突的,单纯的单数组无法同时保留这两个状态,所以我们可以考虑使用一个临时变量来存储两者中一个元素。
如果存储左斜上方的旧数组元素,问题退化为完全背包的单数组,可以正序遍历;但是要注意,如果存储左边的新元素,问题貌似会退化为0-1背包问题的单数组,但因为我们需要不断更新左边的新元素存储到临时变量,因此逆序遍历是不可行的。
滚动数组考虑的是保留整行旧值,单数组考虑的是选择保留哪个旧值。
代码:
递归(超时):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
var longestCommonSubsequence = function(text1, text2) {
const m = text1.length;
const n = text2.length;
const dfs = (i, j) => {
if (i < 0 || j < 0) {
return 0;
}
return Math.max(dfs(i-1, j), dfs(i, j-1), dfs(i-1, j-1) + (text1[i] === text2[j] ? 1 : 0));
}
return dfs(m - 1, n - 1);
};
递归+记忆化搜索:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
var longestCommonSubsequence = function(text1, text2) {
const m = text1.length;
const n = text2.length;
const memo = Array.from({ length : m + 1 }, () => new Array(n + 1).fill(-1));
// memo存储的是每个子问题的解
const dfs = (i, j) => {
if (i < 0 || j < 0) {
return 0;
}
if (memo[i][j] !== -1) {
return memo[i][j];
}
memo[i][j] = Math.max(dfs(i-1, j), dfs(i, j-1), dfs(i-1, j-1) + (text1[i] === text2[j] ? 1 : 0));
return memo[i][j];
}
return dfs(m - 1, n - 1);
};
改写为递推:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
var longestCommonSubsequence = function(text1, text2) {
const m = text1.length;
const n = text2.length;
// dp[i][j] = text1前i个字符与text2前j个字符的LCS长度
const dp = Array.from({ length: m + 1 }, () => new Array(n + 1).fill(0));
// dfs里的memo直接变成了dp要填的表
for (let i = 1; i <= m; i++) {
for (let j = 1; j <= n; j++) {
if (text1[i - 1] === text2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
return dp[m][n];
};
改写为滚动数组:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
var longestCommonSubsequence = function(text1, text2) {
const m = text1.length;
const n = text2.length;
// dp[i][j] = text1前i个字符与text2前j个字符的LCS长度
const dp = Array.from({ length: 2 }, () => new Array(n + 1).fill(0));
// dfs里的memo直接变成了dp要填的表
for (let i = 1; i <= m; i++) {
// 因为用的是i=1的方案,没有将i平移,所以i和j都得从1开始,保证不越界
for (let j = 1; j <= n; j++) {
if (text1[i - 1] === text2[j - 1]) {
dp[i % 2][j] = dp[(i - 1) % 2][j - 1] + 1;
} else {
dp[i % 2][j] = Math.max(dp[(i - 1) % 2][j], dp[i % 2][j - 1]);
}
}
}
return dp[m % 2][n]; // 改成取最后一行对应的位置
};
改写为一个数组:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
var longestCommonSubsequence = function(text1, text2) {
const m = text1.length;
const n = text2.length;
// dp[i][j] = text1前i个字符与text2前j个字符的LCS长度
const dp = new Array(n + 1).fill(0);
// Array.from({ length: 1 }, () => new Array(n + 1).fill(0));
// 这样创建的是[[0,0,...,0]]
for (let i = 1; i <= m; i++) {
let prev = 0; // 保存 dp[j-1] 的旧值(即上一行的 dp[i-1][j-1])
for (let j = 1; j <= n; j++) {
const temp = dp[j]; // 先存下来,这是上一行的 dp[i-1][j]
if (text1[i - 1] === text2[j - 1]) {
dp[j] = prev + 1;
} else {
dp[j] = Math.max(dp[j], dp[j - 1]);
}
prev = temp; // 下一轮 j+1 时,prev 就是上一行的 dp[i-1][j]
}
}
return dp[n]; // 改成取最后一行对应的位置
};
总结:
本题同时集合了0-1背包和完全背包的特点,是典型的双序列DP,但双序列DP没有传统意义上的容量,两个序列要同步推进找最优匹配。如果要很粗略地说,两个序列互为对方的物品数量和容量,不过实际上LCS的两个序列完全对称,没有主次关系,而背包问题的物品是主动选择的,容量是被动约束的。
编辑距离 题目描述:
给你两个单词 word1 和 word2, 请返回将 word1 转换成 word2 所使用的最少操作数 。
你可以对一个单词进行如下三种操作:
- 插入一个字符
- 删除一个字符
- 替换一个字符
示例 1:
1
2
3
4
5
6
输入:word1 = "horse", word2 = "ros"
输出:3
解释:
horse -> rorse (将 'h' 替换为 'r')
rorse -> rose (删除 'r')
rose -> ros (删除 'e')
示例 2:
1
2
3
4
5
6
7
8
输入:word1 = "intention", word2 = "execution"
输出:5
解释:
intention -> inention (删除 't')
inention -> enention (将 'i' 替换为 'e')
enention -> exention (将 'n' 替换为 'x')
exention -> exection (将 'n' 替换为 'c')
exection -> execution (插入 'u')
提示:
0 <= word1.length, word2.length <= 500word1和word2由小写英文字母组成
思路:
本题提及了三种操作,但是实际上还有一个对原序列的操作,就是匹配相同后,可以保留这个字符,这个操作不计入编辑距离,在题目里也是呈现为被跳过。
对于LCS来说,LCS的问题是考虑两个序列中是否有元素要被选入到公共子序列中,如果选入了,公共子序列的长度就要+1。本题因为涉及了增删改,好像已经不能再直接使用选或不选的思路,但实际上还是和LCS的选或不选息息相关。
对于LCS和编辑距离而言,他们的最理想状态是一样的,就是s完全与t相等,这种情况的LCS最大,编辑距离也最小。LCS 和编辑距离都在选,区别在于选了算什么,LCS中的元素能被选中时,选中元素之后会增加公共子序列的长度,而后继续往后运行;而编辑距离选中了元素后可以跳过这个元素(其实也是往后继续运行),保持更改开销不变。而编辑距离问题如果不能选中某个元素(让这个元素被顺利跳过,不增加开销),那么增删改势必是会增加开销的。
一言以蔽之,以选和不选的角度而言,LCS的选或不选是贯穿在s元素和t元素相等或者不等时的,相等一定选,但不等也可能选;而编辑距离问题是相等一定选,不等一定选不了,只能增加开销。
LCS和编辑距离的状态转移方程形式相似,核心原因是它们的状态空间遍历逻辑相同,只是决策目标不同。
此外,编辑距离问题和LCS实际上有一个数学关系:
1
编辑距离 = |s| + |t| - 2 × LCS(s, t) (仅允许删除/插入时)
LCS的目标是最大化公共部分,编辑距离的思路是最小化差异部分。
因为给s插入后的子问题是等价于给t删除后的子问题的,给s插入和给t删除的开销完全相同,也都相当于增加开销后跳过这个元素,所以可以把针对s的插入等价为i不变,而j-1。

因此在递归我们考虑边界条件时,当某个字符串为空,要把另一个字符串都去掉(s为空,需要插入,等价为清空t;t为空,等价为需要清空s)。
代码:
递归:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
var minDistance = function(word1, word2) {
const n = word1.length;
const m = word2.length;
const dfs = (i, j) => {
if (i < 0) {
return j + 1;
}
if (j < 0) {
return i + 1;
}
if (word1[i] === word2[j]) {
return dfs(i - 1, j - 1);
} else {
return Math.min(dfs(i - 1, j), dfs(i, j - 1), dfs(i - 1, j - 1)) + 1;
}
}
return dfs(n - 1, m - 1);
};
递归+记忆化搜索:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
var minDistance = function(word1, word2) {
const n = word1.length;
const m = word2.length;
const memo = Array.from({ length : n + 1 }, () => new Array(m + 1).fill(0));
const dfs = (i, j) => {
if (i < 0) {
return j + 1;
}
if (j < 0) {
return i + 1;
}
if (memo[i][j] !== 0) {
return memo[i][j];
}
if (word1[i] === word2[j]) {
memo[i][j] = dfs(i - 1, j - 1);
} else {
memo[i][j] = Math.min(dfs(i - 1, j), dfs(i, j - 1), dfs(i - 1, j - 1)) + 1;
}
return memo[i][j];
}
return dfs(n - 1, m - 1);
};
递归:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
var minDistance = function(word1, word2) {
const n = word1.length;
const m = word2.length;
const dp = Array.from({ length: n + 1 }, () => new Array(m + 1).fill(0));
// 边界条件改写为初始条件:s为空,只能全插入;t为空,只能全删除
for (let i = 0; i <= n; i++) dp[i][0] = i;
for (let j = 0; j <= m; j++) dp[0][j] = j;
for (let i = 1; i <= n; i++) {
for (let j = 1; j <= m; j++) {
if (word1[i - 1] === word2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1];
} else {
dp[i][j] = Math.min(dp[i - 1][j], dp[i][j - 1], dp[i - 1][j - 1]) + 1;
}
}
}
return dp[n][m];
};
单数组:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
var minDistance = function(word1, word2) {
const n = word1.length;
const m = word2.length;
const dp = new Array(m + 1).fill(0);
for (let j = 0; j <= m; j++) dp[j] = j;
for (let i = 1; i <= n; i++) {
let prev = dp[0]; // 保存左上角旧值
dp[0] = i; // 边界:dp[i][0] = i
for (let j = 1; j <= m; j++) {
let temp = dp[j]; // 记录当前值,下一轮当左上角用
if (word1[i - 1] === word2[j - 1]) {
dp[j] = prev;
} else {
dp[j] = Math.min(dp[j], dp[j - 1], prev) + 1;
}
prev = temp;
}
}
return dp[m];
};
总结:
这题之前是hard,改成mid之后,单纯的递归都超时了,笑死。
此外因为这题的依赖和LCS是一样的,所以也可以改写成滚动数组和单数组。